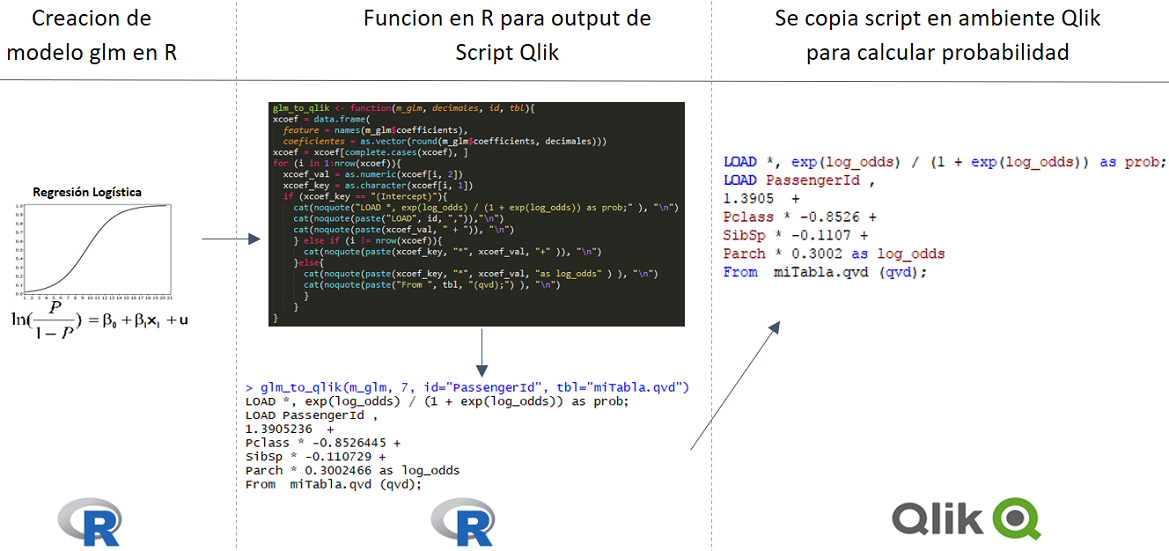
El siguiente script identifica el genero de un nombre dado, utilizando una lista de nombres+genero. Los valores que devuelve son: {m, f, a}, correspondientes a masculino, femenino o ambiguo.
La lista contiene más de 46mil nombres + genero, unificados de las siguientes fuentes:
• Lista de nombres de la librería nltk
• Lista nombres de la librería gender_guesser
• Lista de nombres argentinos publicados aqui
También se hicieron otras modificaciones para nombres hispanos, como borrar apellidos, agregar diminutivos, nombres cortos, alias, entre otros.
R script:
libs<-c('tm','stringi') lapply(libs,require, character.only= TRUE) # FUNCIONES ------------------------------ clean_txt <- function(txt){ txt <- stri_trim(gsub('[[:punct:][:digit:] ]+',' ',tolower(txt))) return(strsplit(txt, " ")[[1]]) } get_gender2 <- function(nombre, lista_nombres="") { nombre <- clean_txt(nombre) nombre <- subset(nombre, nombre %in% lista_nombres) mylist <- list() mylist[c("f", "m","a")] <- 0 for (i in 1:length(nombre)){ g <- as.character(df[which(df$nombre == nombre[i]),"genero"]) g <- ifelse(identical(g, character(0)), 'a', g) if(i==1){ mylist[[g]] <- mylist[[g]] + 2 } else{ mylist[[g]] <- mylist[[g]] + 1 } g2 = sapply(mylist, function(x) x[which.max(abs(x))]) return(names(g2[g2==max(g2)])[1]) } } # DATOS --------------------------------- path <- 'https://www.dropbox.com/s/edm5383iffurv4x/nombres.csv?dl=1' df <- read.csv(path, sep=",", colClasses = "character") get_gender2("jose maria altagracia", df$nombre)